
Setelah kita mencoba berbagai Metode dan Peran Data mining dengan berbagai algoritma. Kali ini saya akan membahas bagaimana kita menguji atau mengevaluasi Model yang kita buat. Kenapa harus dievaluasi ? Bukankah hasil tersebut bisa langsung digunakan??
Evaluasi data mining ini digunakan untuk mengukur ketepatan atau jumlah error yang ada pada model yang sudah kita bangun. Hal ini bertujuan agar kita mengetahui seberapa optimal model kita untuk memecahkan suatu permasalahan. Selain itu disini kita bisa menguji kehandalan dataset yang kita punya. Apakah dataset tersebut relevan dan handal untuk diekstrak pengetahuaanya.
Evaluasi data mining ini bisa digunakan untuk komparasi atau pembanding antara algoritma yang digunakan. Semisal kita melakukan estimasi data konsumsi minyak pemanas ruang (baca : [Belajar DM] Metode Estimasi Data Mining) dengan menggunakan algoritma Regresi linier, kemudian kita coba buat pula model dengan menggunakan algoritma neural network. Dengan evaluasi ini kita bisa membandingkan algoritma mana yang bisa memberikan model yang handal dan sesuai dengan kebutuhan.
Berikut adalah Metode Evaluasi data mining berbasarkan 5 peran data mining
-
Estimasi
Untuk data mining estimasi evaluasi yang digunakan adalah mengukur tingkat error. Biasanya menggunakan Root Mean Square Error (RMSE). Menurut Wikipedia
RMSE (Root Mean Square Error) adalah suatu matrik untuk mengukur error dengan cara rata-rata selisih kuadrat antara nilai taksiran dan nilai sebenarnya kemudian hasilnya di kuadratkan agar menjadi positif dengan kemudian di cari akarnya. Metode estimasi yang mempunyai RMSE lebih kecil dikatakan lebih akurat daripada metode estimasi yang mempunyai RMSE lebih besar.
Alur dari RMSE adalah sebagai berikut
- Hasil Estimasi dari model dikurangi hasil nyata
- Selisihnya di di kuadratkan agar hasilnya positif
- kemudian dicari reratanya dan di akar
Rumus RMSE sebagai berikut

Dimana
- At = Nilai data Aktual
- Ft = Nilai hasil peramalan
- N= banyaknya data
- ∑ = Summation (Jumlahkan keseluruhan nilai)
untuk praktikum silahkan buka project orange3 kita sebelumnya, mengenenai estimasi heating oil (baca : [Belajar DM] Metode Estimasi Data Mining)

Selanjutnya kita tambahkan widget Test and Score yang ada pada tab Evaluate. Hubungkan dengan Data set di Widget Edit Domain dan Model Linear Regression, seperti dibawah ini

Kemudian buka widget Test and Score dan kita bisa lihat hasilnya

Ada beberapa metode untuk melakukan evaluasi semisal disini saya menggunakan cross validation, Cross-validasi, atau bisa disebut estimasi rotasi adalah sebuah teknik validasi model untuk menilai bagaimana hasil statistik analisis akan menggeneralisasi kumpulan data independen. Dimana Data test dan data training akan diujikan semua sebanyak fold atau jumlah pembagian datanya.
Dari Metode Cross Validation diatas kita bisa mengetahui bahwa nilai RMSE adalah 24,064. Sekerang coba kita bandingkan dengan metode Random Sampling. Dimana pengambilan data test dan trainingnya diambil secara acak berdasarkan jumlah data dan prosentasi banyak data yang akan diuji.

Selisihnya tidak terlalu jauh. Hal ini dapat disimpulkan bawah model yang kita buat cukup optimal.
-
Prediksi/Forecasting
Seperti yang kita tahu untuk peran data mining ini mirip dengan estimasi namin datanya ada yang mengandung time series. Cara melakukan evaluasinya adalah dengan mengukur tingkat error dari hasil model. Kita bisa menggunakan Root Mean Square Error (RMSE).
Silahkan buka project workflow kita mengenai prediksi jumlah penumpang pesawat (baca : [Belajar DM] Metode Forecasting Data Mining)

Kemudian kita tambahkan widget Model Evaluation di Tab Time Series. Hubungkan Data set dari widget As Timeseries dan Widget ARIMA Model dengan Widget Model Evaluation seperti dibawah ini

Kita lihat hasilnya dengan cara klik Widget Model Evaluation

Kita bisa mengetahui bahwa model ARIMA yang kita buat memiliki score RMSW sebesar 62,0. Untuk Model evaluasi ini menggunakan metode cross validation. Hal ini ditandai dengan adanya penentuan number of folds. Silahkan lakukan kalibrasi agar mendapatkan hasil yang optimal.
-
Klasifikasi
Untuk klasifkasi metode Evaluasi yang digunakan adalah akurasi model, untuk mengukurnya bisa menggunakan Confusion Matrix dan Area Under Curve (AUC) / ROC (Receiver Operating Characteristics).
Silahkan buka kembali workflow kita mengenai penentuan main golf (baca : [Belajar DM] Metode Klasifikasi Data Mining)
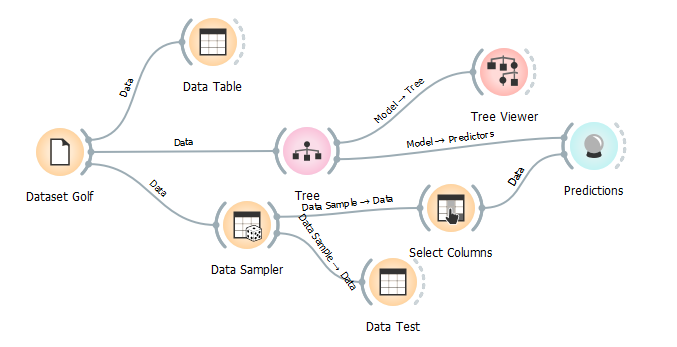
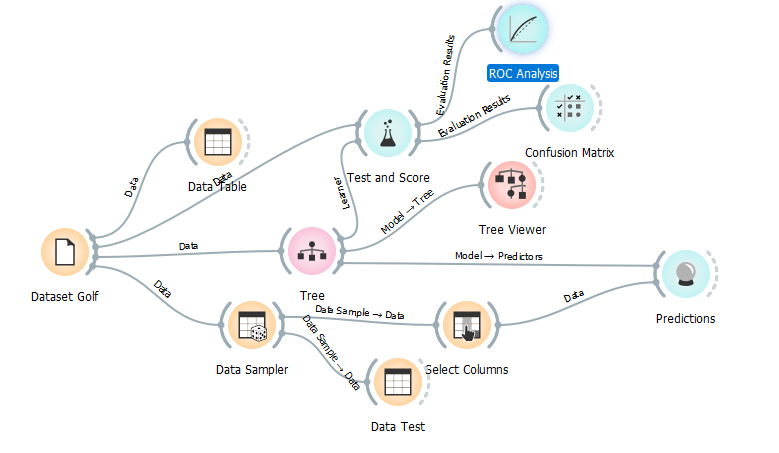
Selanjutnya kita tambahkan widget Test and Score kemudian hubungkan dengan Widget Tree dan Dataset Golf seperti dibawah ini
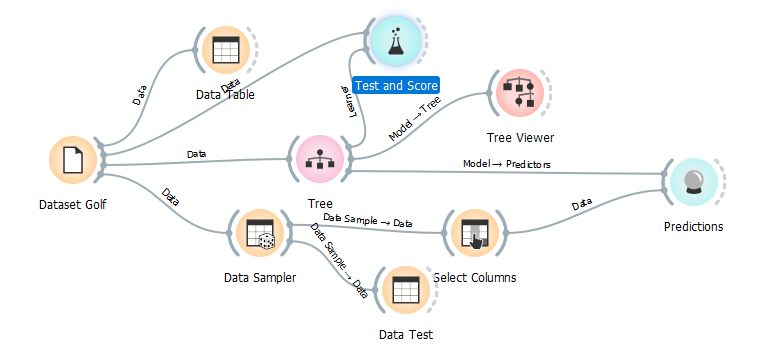
Kemudian kita hubungkan Hasil Test and Score dengan Widget Confusion Matrix
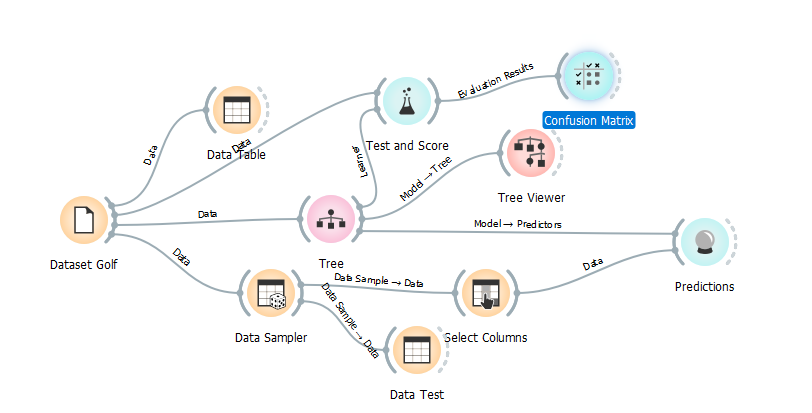
Berikut adalah hasil Confusion Matrix nya
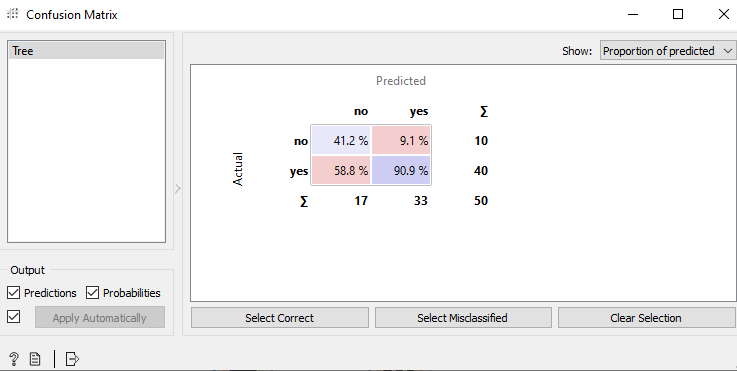
Dalam Confusion Matrix Ada data actual dan data predicted. Data actual adalah hasil sebenarnya sedangkan data predicted adalah hasil prediksi dari model yang dibuat. Berikut adalah cara membacanya
- Data Actual NO atau tidak bermain golf dan Data predicted NO atau tidak bermain sebesar 41.2% ini dinamakan True Negative (TP)
- Data Actual YES atau bermain dan Data hasil Predicted NO atau tidak bermain sebesar 58.8% ini disebut False Negative (FN)
- Data Actual NO namun hasil prediksi YES ini disebut False Positive (FP) sebesar 9,1%
- Sedangkan Data Actual YES dan Hasil prediksi atau data predicted yes sebesar 90.9% dsebut True Positive (TP)
Untuk menghitung accuracy atau ketepatan model rumusnya adalah
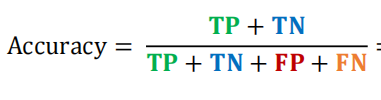
Sehingga jika kita cari hasil accusary sesuai dengan matrix diatas adalah sebesar 74% dari bisa disimpulkan bahwa model yang dibuat cukup akurat dalam memprediksi data. Anda bisa melakukan kalibrasi dengan mengkonfigurasi Widget Tree sehingga memperoleh hasil yang optimal.
Selain itu kita jua bisa melakukan evaluasi dengan menggunakan widget ROC (Receiver Operating Characteristics) seperti dibawah ini
Dari ROC tersebut kita bisa melihat AUC (Area Under Curve) seperti dibawah ini
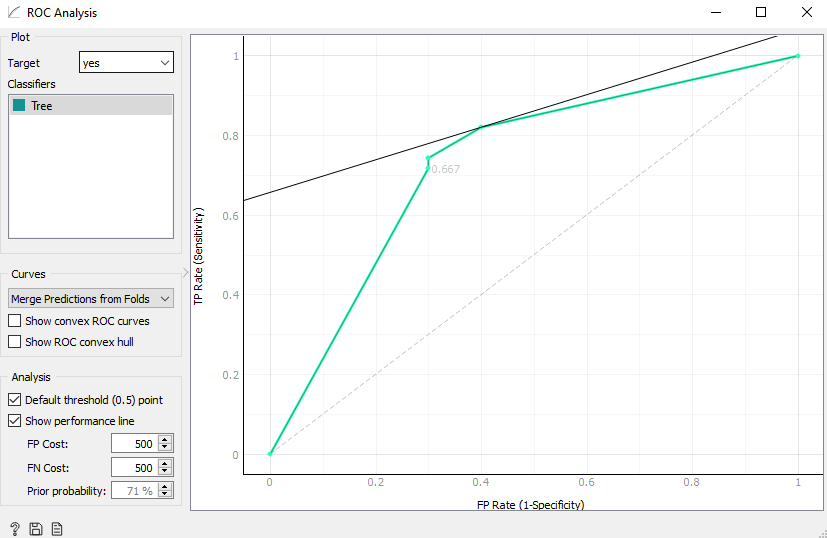
Kita bisa lihat hasil AUC untuk nilai TP ataupun FP. Berikut adalah rentang nilai AUC menurut Gorunescu, 2011
-
0.90 – 1.00 = excellent classification
-
0.80 – 0.90 = good classification
-
0.70 – 0.80 = fair classification
-
0.60 – 0.70 = poor classification
-
0.50 – 0.60 = failure
-
Klastering
Untuk Metode ini cara evaluasinya adalah dengan menggunakan silhouette coefficient. Metode ini berfungsi untuk menguji kualitas dari cluster yang dihasilkan. Metode ini merupakan metode validasi cluster yang menggabungkan metode cohesion dan Separation. Untuk menghitung nilai silhoutte coefisient diperlukan jarak antar dokumen dengan menggunakan rumus Euclidean Distance.
tahapan untuk menghitung nilai silhoutte coeffisien adalah sebagai berikut :
- Untuk setiap objek i, hitung rata-rata jarak dari objek i dengan seluruh objek yang berada dalam satu cluster. Akan didapatkan nilai rata-rata yang disebut ai.
- Untuk setiap objek i, hitung rata-rata jarak dari objek i dengan objek yang berada di cluster lainnya. Dari semua jarak rata-rata tersebut ambil nilai yang paling kecil. Nilai ini disebut bi.
- Setelah itu maka untuk objek i memiliki nilai silhoutte coefisien :
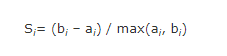
Silahkan buka workflow clustering Bunga Iris (baca : [Belajar DM] Metode Klastering Data Mining)
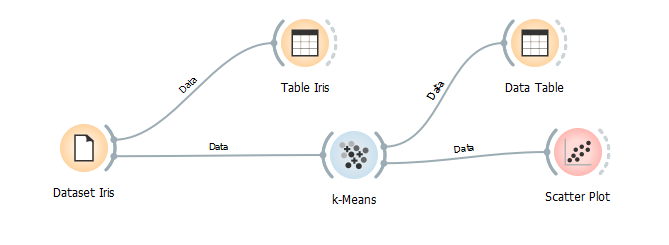
Kita bisa cek secara langsung nilai silhoutte di widget k-Means saat kita menentukan nilai K atau banyak klaster yang akan terbentuk
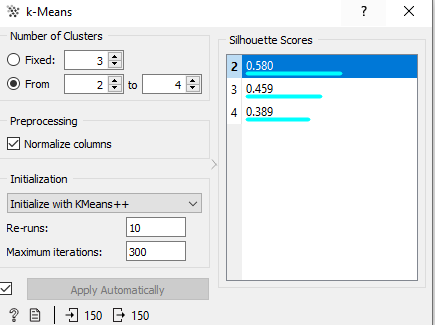
Diatas kita bisa melihat silhoutte score dimana klasifikasi adalah sebagai berikut
- 0.7 < SC <= 1 Strong Stucture
- 0.5 < SC <= 0.7 Medium Structure
- 0.25 < SC <= 0.5 Weak Structure
- SC <= 0.25 No structure
Kita bisa menghubungkan dengan widget Silhoutte Plot di Tab Visualize seperti dibawah ini
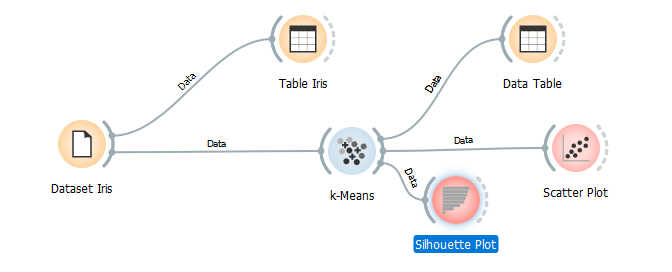
Berikut adalah hasilnya
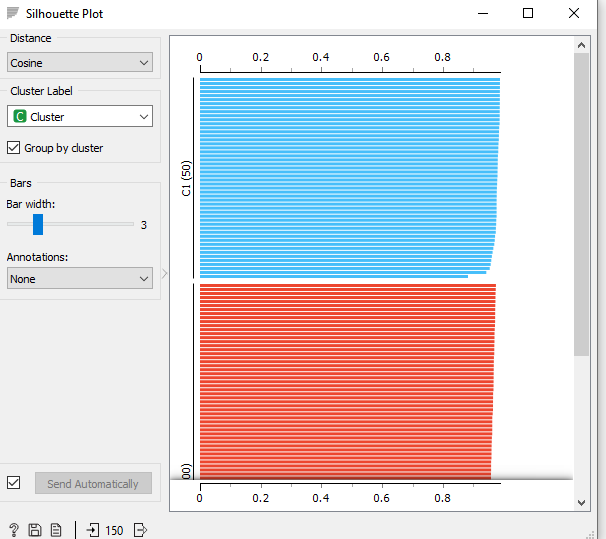
Silhoutte terbaik adalah yang mendekati 1 sedangkan yang negatif berarti tidak baik. Kita bisa melakukan kalibrasi nilai K berdasarkan hasil diatas.
-
Asosiasi
Seperti yang sudah kita ketahui bahwa aturan asosiasi (baca : [Belajar DM] Metode Asosiasi Data Mining) dalam data mining menggunakan support dan confidence. Namun ada nilai yang jua dipertimbangkan yaitu lift ratio. Lift rasio adalah jenis pengujian yang digunakan untuk melihat kuat tidaknya aturan asosiasi dalam data mining khususnya pada Algoritma A Priori.
Rumusnya adalah
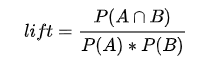
Silahkan buka workflow mengenai data mining transaksi sebelumnya
Dari data diatas kita bisa memperoleh Rules sebagai berikut
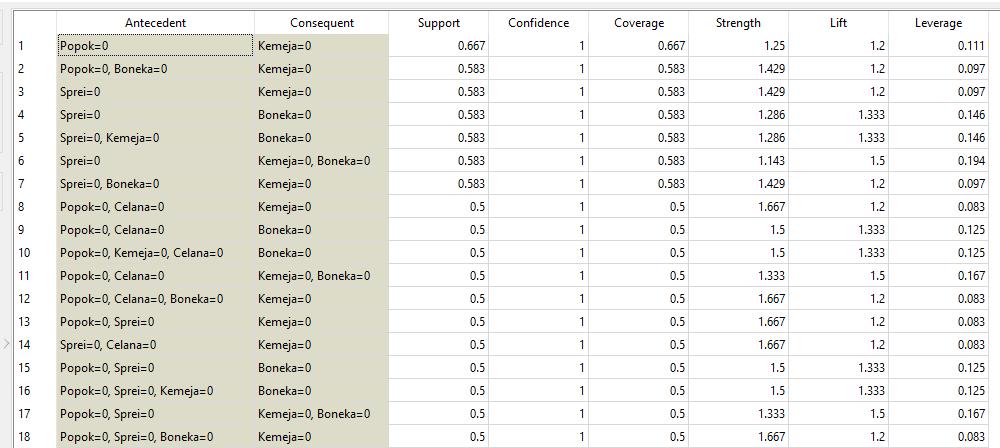
Pada kolom Lift merupakan lift ratio dari tiap asosiasi. Dimana semakin tinggi nilainya berarti semakin kuat aturan asosiasi tersebut.
Demikian pembahasan mengenai metode evaluasi data mining. Jika ada pertanyaan silahkan masukan dikolom komentar dibawah ini.

Kalau disebutkan referensi khususnya jurnal yang digunakan sebagai landasannya pasti sangat membantu pak
baik terima kasih atas sarannya, panduan diatas adalah catat oprek saja, jadi masih banyak kekurangannya